
기존에 data를 zip함수로 합친 반면에, numpy.column_stack으로 나란히 붙일수 있다.
앞서 index로 섞은 training, test shuffle을 sklearn.model_selection / train_test_split() 함수로 할 수 있다.
근데, target 데이터를 전달해, 클래스 비율에 맞게 데이터를 나누고 싶다면, stratify 인자를 추가한다.

[25,150]을 예측하면, 거리가 멀어도, 0으로 예측된다. x축에 비해 y축은 조금만 멀어도 거리가 확 멀어지기 때문에 기준을 정한다.
여기서는 y값이 x값보다 훨씬 범위가 다르다. 이러한 경우, 두 특성의 스케일(scale)이 다르다. 고 말한다.


이런 알고리즘들은 샘플 간의 거리에 영향을 많이 받으므로 제대로 사용하려면 특성값을 일정한 기준으로 맞춰 주어야 합니다. => 데이터 전처리(data preprocessing)
여기서는 표준점수(standard score)를 사용한다.
표준 점수란? 각 특성값이 0에서 표준편차의 몇 배만큼 떨어져 있는지 나타낸다.
데이터 전처리를 위해, 브로드캐스팅 연산을 진행한다. -> train_scaled,

numpy.column_stack으로 zip()을 대체, fish_target은 concatenate로 생성

기존 shuffle을 대체하는 from sklearn.model_selection import train_test_split
target 비율 맞추기 위한 stratify = (target)



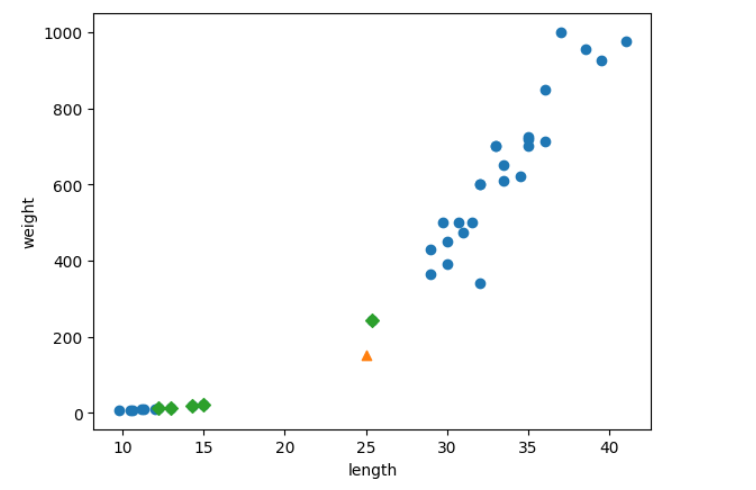

kn.kneighbors([[25,150]]) -> distances, indexes가 출력된다.


x축과 y축의 길이를 똑같이 맞추면, x축의 범위가 좁다.
이러한 범위가 매우 다른경우를, 두 특성의 스케일(scale)이 다르다. 고도 한다.
표준점수는 (x-m)/sigma로 진행. 통계에서 이러한 점수를 z점수 라고 한다.
평균과 표준편차를 구하기 위해, axis=0으로 연산을 진행,
표준점수를 만들기 위해 브로드 캐스팅 연산을 진행한다.



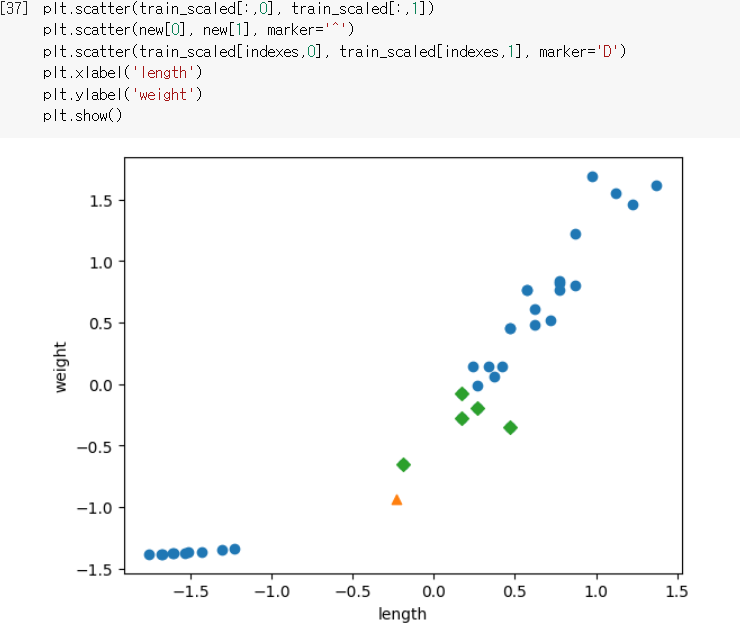
물론, 예측하려는 값도 표준점수로 바꿔줘야 한다.
표준점수로 바꾼 후, 같은 과정을 진행하면 그래프처럼 바람직하게 완성된다.
'DATA & AI > HG ML&DL' 카테고리의 다른 글
| [HG ML&DL] 03. 회귀 알고리즘과 모델 규제 (3) - 특성 공학과 규제 (0) | 2023.05.01 |
|---|---|
| [HG ML&DL] 03. 회귀 알고리즘과 모델 규제 (2) - 선형 회귀 (0) | 2023.05.01 |
| [HG ML&DL] 03. 회귀 알고리즘과 모델 규제 (1) - k-최근접 이웃 회귀 (0) | 2023.05.01 |
| [HG ML&DL] 02. 데이터 다루기 (1) (0) | 2023.04.28 |
| [HG ML&DL] 01. 나의 첫 머신러닝 (0) | 2023.04.28 |



