k-최근접 이웃 회귀 모델로 전부 회귀 가능하다면 얼마나 좋을까? 과연 그런지 확인해볼까?


여기까지 데이터 준비하고, 예상해보면 길이가 50cm인 농어는 1033g으로 예측됩니다.
이때, 모델을 KNeighborsRegressor를 사용하고, n_neighbors 인자로 k의 값을 지정했습니다.

그림으로 표현하면 위와 같습니다.

근데, 100cm여도 여전히 같은 값을 예측합니다.
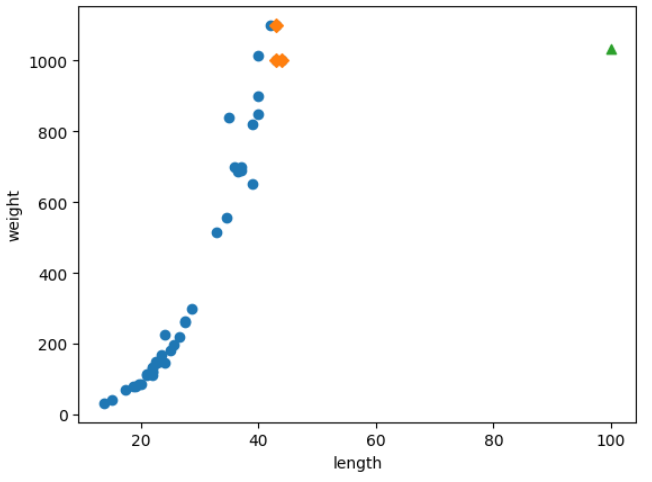
k-최근접 회귀 알고리즘의 단점이나 문제점을 발견했죠.
그렇다면 무슨 알고리즘이 있을까?


선형회귀(linear regression)은 널리 사용되는 대표적인 회귀 알고리즘입니다.

sklearn.linear_model / LinearRegression -> 선형회귀 클래스
y = ax+b와 같은 1차 방정식 회귀입니다.
이때, 인자는 lr.coef_, lr.intercept_ 인자에 저장되어있습니다.
이러한 인자, 머신러닝 알고리즘이 찾은 값을 모델 파라미터(model parameter)라고 한다.
이러한 최적의 모델 파라미터를 찾는 과정을 모델 기반 학습이라고 합니다.
k-최근접 이웃과 같은 훈련 세트를 저장하는 것이 훈련의 전부인 학습을 사례 기반 학습이라고 합니다.

- 다항 회귀

train_input, test_input 값을 2열 행렬로 바꿔서 2차 방정식의 선형 회귀를 사용하려고 합니다.
-> 무게 = 1.01 X 길이^2 - 21.55 X 길이 + 116.05 와 같은 방정식이 나오죠.

그림으로 표현하면 위와 같이 나옵니다.
이러한 다항식을 사용한 회귀를 다항회귀(polynomial regression) 이라고 합니다.

점수가 둘다 매우 좋아졌죠.
결국, LinearRegression() 객체에 fit(train_input, train.target) 해주는 것은, 다항식의 모델 파라미터를 구하는 과정!
'DATA & AI > HG ML&DL' 카테고리의 다른 글
| [HG ML&DL] 04. 다양한 분류 알고리즘 (1) - 로지스틱 회귀 (0) | 2023.05.01 |
|---|---|
| [HG ML&DL] 03. 회귀 알고리즘과 모델 규제 (3) - 특성 공학과 규제 (0) | 2023.05.01 |
| [HG ML&DL] 03. 회귀 알고리즘과 모델 규제 (1) - k-최근접 이웃 회귀 (0) | 2023.05.01 |
| [HG ML&DL] 02. 데이터 다루기 (2) - 데이터 전처리 (0) | 2023.04.28 |
| [HG ML&DL] 02. 데이터 다루기 (1) (0) | 2023.04.28 |



