
머신 러닝은 크게 target이 존재하는 지도학습, target이 없는 비지도 학습으로 나뉜다.
지도 학습에서 데이터와 정답을 입력(input)과 타겟(target)이라고 하고, 이를 한꺼번에 훈련 데이터(training data)라고 부른다.
그리고, 평가에 사용하는 데이터를 테스터 세트(test set), 훈련에 사용하는 데이터를 훈련 세트(train set)라고 부른다.
데이터가 여러개 있는 경우, 하나의 데이터를 샘플(sample)이라고 한다.

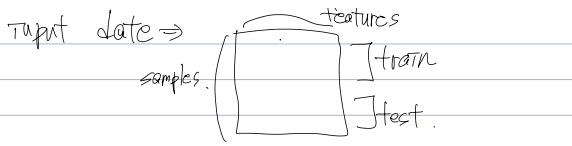
훈련하는 데이터와 테스트하는 데이터에는 데이터가 골고루 섞여 있어야 한다. 골고루 섞여 있찌 않으면 샘플링이 한쪽으로 치우쳤다는 의미로 샘플링 편향(sampling bias)라고 부른다.
numpy를 이용해서, 배열로 바꾸고, 샘플링 편향을 막기위해, np.random.shuffle() 사용.
그림의 마지막 부분은 input data를 잘 못 썼다..
2차원 배열로 표현한 경우, samples, features, 이를 나눠서 train set, test set으로 나눈다.


섞지 않고, sampling bias로 인한 정확도 0이 출력된 코드를 위에서 보여준다.
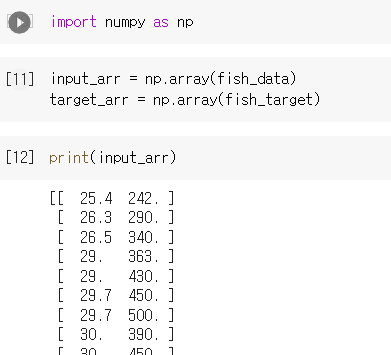
기존 fist_data의 배열을 input_arr, fist_target의 배열을 target_arr으로 선언.

seed()로 상황을 고정하고, 자료가 섞이는 것이 아닌, index를 섞는다.

놀랍게도 index 배열을 인덱스로 넣으면, 각 인덱스에 맞는 input_arr의 원소를 차례로 넣어준다.

잘 섞였는지 확인하기 위한 그림

새로 훈련한 모델의 정확도를 보여준다.
'DATA & AI > HG ML&DL' 카테고리의 다른 글
| [HG ML&DL] 03. 회귀 알고리즘과 모델 규제 (3) - 특성 공학과 규제 (0) | 2023.05.01 |
|---|---|
| [HG ML&DL] 03. 회귀 알고리즘과 모델 규제 (2) - 선형 회귀 (0) | 2023.05.01 |
| [HG ML&DL] 03. 회귀 알고리즘과 모델 규제 (1) - k-최근접 이웃 회귀 (0) | 2023.05.01 |
| [HG ML&DL] 02. 데이터 다루기 (2) - 데이터 전처리 (0) | 2023.04.28 |
| [HG ML&DL] 01. 나의 첫 머신러닝 (0) | 2023.04.28 |



