혼자 공부하는 머신러닝 + 딥러닝 책으로 공부 했습니다.
머신러닝에서 SVM을 제외한 이론 및 학습에 대해 배웠고, 비지도학습에서는 k-means 알고리즘에 대해 공부했는데, 다른 군집 알고리즘도 많아서 차차 공부하고 정리하겠습니다.

인공지능, 머신러닝, 딥러닝에 대한 가벼운 정리

기본적인 머신러닝으로 classfication을 진행하려고 한다.
이때, 생선 분류를 하기위해 데이터셋을 가져온다. 데이터의 특징을 feature라고 하자.

분류하는 방법은 k-최근접 이웃방법으로 분류해보자.

위에서 길이와 무게와 같은 특징을 특성(feature)라고 하자.
이에 대한 그림을 그리면 아래와 같다.

빙어 데이터도 똑같이 준비해서 그림을 그려보면 다음과 같다.

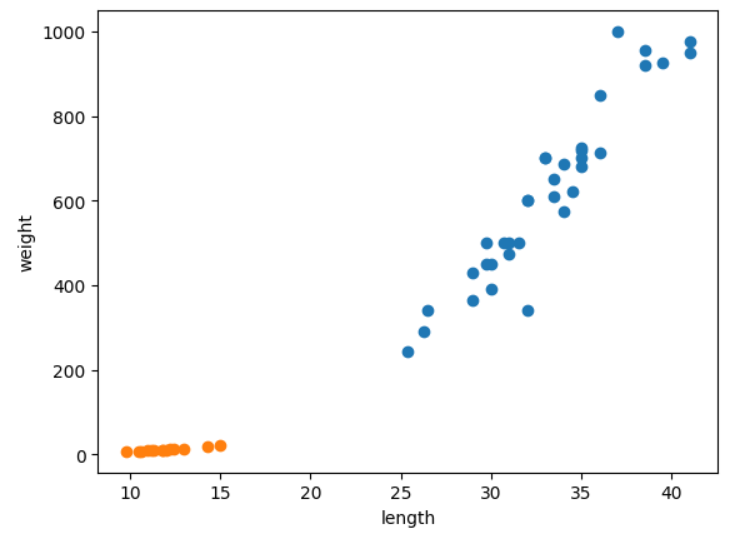
도미에 비해 빙어 데이터 차이들이 너무 작아서 산점도로 표시하면 위와 같이 나온다.
따로 배열에 선언했던 특성들을 묶어서 저장하자.

그리고, 정답(target)을 주고, 훈련시켜보자.

kn은 KNeighborsClassifier 객체
fit()은 모델을 훈련(training)시키는 메서드
score()로 모델을 평가하고, 나온 값을 정확도(accuracy)라고 한다.
좀 더 자세히 보자.

초록 삼각형이 무슨 생선으로 분류될까?

훈련시킨 모델로 predict 해본결과 도미(1)로 분류되었음을 알 수 있습니다.
kn의 ._fit_X에 훈련한 데이터가 들어있다.

kn의 ._y의 데이터에 target 데이터가 들어있다.
KNeighborsClassifier() 클래스의 parameter로 n_neighbors 인자로 근접 갯수(참고 데이터)를 정할 수 있다.
최대로 정하면, 과반수인 도미데이터로 인식하기 때문에 위와같은 정확도가 나온다.
- KNeighborsClassifier()
: k-최근접 이웃 분류 모델을 만드는 사이킷런 클래스, n_neighbors 매개변수로 이웃의 개수 지정, default = 5
- fit()
: 사이킷런 모델을 훈련할 때 사용하는 메서드, 훈련에 사용한 특성과 정답 데이터 전달.
- predict()
: 사이킷런 모델을 훈련하고 예측할 때 사용하는 메서드, 특성 데이터 하나만 매개변수로 받는다.
- score()
: 훈련된 사이킷런 모델의 성능을 측정합니다. 처음 두 매개변수로 특성(feature)과 정답 데이터(target) 전달
'DATA & AI > HG ML&DL' 카테고리의 다른 글
| [HG ML&DL] 03. 회귀 알고리즘과 모델 규제 (3) - 특성 공학과 규제 (0) | 2023.05.01 |
|---|---|
| [HG ML&DL] 03. 회귀 알고리즘과 모델 규제 (2) - 선형 회귀 (0) | 2023.05.01 |
| [HG ML&DL] 03. 회귀 알고리즘과 모델 규제 (1) - k-최근접 이웃 회귀 (0) | 2023.05.01 |
| [HG ML&DL] 02. 데이터 다루기 (2) - 데이터 전처리 (0) | 2023.04.28 |
| [HG ML&DL] 02. 데이터 다루기 (1) (0) | 2023.04.28 |



