- 조건으로 검색하기
masking operation
df = pd.DataFrame(np.random.rand(5,2), columns=["A","B"])
print(df["A"] < 0.5)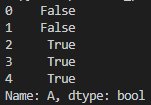
print(df[(df["A"]<0.5) & (df["B"]>0.3)])
print(df.query("A<0.5 & B>0.3"))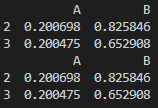
마스킹연산을 query를 사용해서도 할 수 있다.
print(df["Animal"].str.contains("Cat"))
print(df.Animal.str.match("Cat"))
문자열은 위와 같이 검색가능하다.
- apply
df = pd.DataFrame(np.arange(5), columns=["Num"])
# print(df["Num"].apply(lambda x: x**2))
df["Square"] = df.Num.apply(lambda x: x**2)
print(df)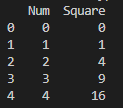
apply(function) 메소드는 map처럼 원소별로 함수를 각각 입력한 값을 받을수 있다.
df = pd.DataFrame(columns=["phone"])
df.loc[0] = "010-1234-1234"
df.loc[1] = "공일공-일이삼사-사삼이일"
df["preprocess_phone"] = ''
dic = {
"공":"0",
"일":'1',
"이":'2',
"삼":'3',
"사":'4',
"-":'',
".":""
}
def func(x):
for a, b in dic.items():
x = x.replace(a,b)
return x
df["preprocess_phone"] = df["phone"].apply(func)
print(df)
print(df.replace({"010-1234-1234":"안녕하세요", "공일공-일이삼사-사삼이일":"저에요"}))
값만 변경하고 싶을때, replace 메서드로 가능
inplace=True를 같이 작성하면, 바로 df가 변경
- groupby
만약 같은 값을 가진 행끼리 그룹을 만들고 싶다면?
df = pd.DataFrame({'key':["a",'b','c',"a",'b','c'], 'data1':[1,2,3,1,2,3],'data2':[1,3,4,5,6,7]})
print(df.groupby('key'))
print(df.groupby('key').sum())
print(df.groupby(['key','data1']).sum())
groupby로 그룹을 만들었을때, 연산이 없는경우, object로 출력된다.
- aggregate
집계를 한번에 계산하는 메소드
print(df.groupby('key').aggregate(['min',np.median,max]))
print(df.groupby('key').aggregate({'data1':"min", 'data2':np.sum}))
- filter
참인 값만 출력해주는 메소드
print(df.groupby('key').filter(lambda x: x['data2'].mean()>3))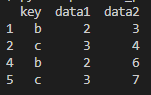
- apply
groupby를 통해 묶인 데이터에 함수 적용하는 메소드
print(df.groupby('key').apply(lambda x: x.max()- x.min()))
- get_group
groupby로 묶인 데이터에서 key값으로 데이터를 가져올수 있는 메소드
- MultiIndex& pivot_table
df = pd.DataFrame(
np.random.randn(4,2),
index=[['A','A','B','B'],[1,2,1,2]],
columns=['data1','data2']
)
print(df)
Index를 계층적으로 만들수 있다.
df = pd.DataFrame(
np.random.randn(4,4),
columns=[['A','A','B','B'],[1,2,1,2]],
)
print(df)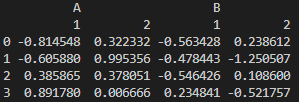
column index도 계층적으로 생성 가능
나중에 다양한 데이터가 있는 파일을 가져와서 pivot_table도 만들어보자.
'Language > Python' 카테고리의 다른 글
| Pandas_Operations&function, Sort (0) | 2023.02.26 |
|---|---|
| Pandas_Series, DataFrame (0) | 2023.02.24 |
| Numpy_Broadcasting, masking (0) | 2023.02.23 |
| Numpy_Indexing, Slicing, Operator (1) | 2023.02.23 |
| Numpy_Create Array (0) | 2023.02.23 |

