Pandas란?
- 파이썬 라이브러리
- 구조화된 데이터를 효과적으로 처리하고 저장
- Array 계산에 특화된 NumPy를 기반으로 설계
- 행과 열로 이루어진 데이터 객체를 만들어 다룰 수 있어, 데이터 처리와 분석하기 유용함
- Pandas 자료구조
- Series: 1차원
- DataFrame: 2차원
- Panel: 3차원
- Series
: numpy array가 보강된 형태
Data와 Index로 이루어져 있다.
import pandas as pd
data = pd.Series([1,2,3,4])
print(data)
Index를 따로 선언해주지 않으면, 0부터 시작된다.
위 사진 기준, 좌측 Index, 우측 Data
data = pd.Series([1,2,3,4],index=['a','b','c','d'])
print(data)
인덱스를 가지고 있는데, 이름을 붙여 저장가능하다. Dictionary의 key, value 형식으로 접근가능하다.
data = pd.Series([1,2,3,4],index=['a','b','c','d'], name="시리즈")
data['c'] = 5
print(data)Series는 name도 선언가능하고, dictionary처럼 선언후 값을 변경가능하다.

dict = {
'LCM' : 178,
'SJH' : 207,
'HJW' : 175
}
Ser = pd.Series(dict)
print(dict,"\n", Ser)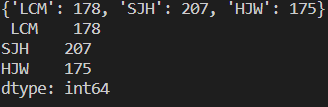
딕셔너리를 Series로 변환가능 하다.
기존 key가 Index가 되고, value가 data가 된다.
- DataFrame
: 1차원인 Series의 모임, 행과 열을 이룬 데이터
dict1 = {
'LCM' : 178,
'SJH' : 207,
'HJW' : 175
}
dict2 = {
'LCM' : 1,
'SJH' : 2,
'HJW' : 3
}
Ser1 = pd.Series(dict1)
Ser2 = pd.Series(dict2)
nameDF = pd.DataFrame({
'tall' : Ser1,
'order' : Ser2
})
print(nameDF)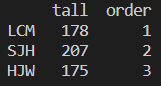
각 Series가 열이 되고, 행렬형식으로 DataFrame을 만들수 있다.
print(nameDF.index)
print(nameDF.columns)
print(nameDF['tall'])각 index, columns를 뽑아서 볼수 있다. dictionary처럼 뽑아내면 Series가 출력된다.
Ser3 = nameDF['tall']/nameDF['order']
nameDF['div'] = Ser3
print(nameDF)
Series도 numpy array처럼 각 원소별 연산을 지원한다.
그리고 dictionary처럼 새로운 Series를 추가할 수 있다.
nameDF.to_csv("./first.csv")
printDF = pd.read_csv('./first.csv')
print(printDF)저장과 불러오기를 지원해준다. 이는 xlsx파일도 가능하다.
- 내용 정리
새로운 라이브러리 Pandas의 기본 자료형 Series와 DataFrame을 다루었습니다.
Series의 큰 특징은 index에 이름을 붙일 수 있다.
DataFrame은 Series들의 모임
'Language > Python' 카테고리의 다른 글
| Pandas 심화 (0) | 2023.02.26 |
|---|---|
| Pandas_Operations&function, Sort (0) | 2023.02.26 |
| Numpy_Broadcasting, masking (0) | 2023.02.23 |
| Numpy_Indexing, Slicing, Operator (1) | 2023.02.23 |
| Numpy_Create Array (0) | 2023.02.23 |

