- Pandas 연산& 함수
- 누락된 데이터 체크
print(DF.isnull())
print(DF.notnull())
isnull()은 각 데이터가 비어있으면(nan, None) True, 아니면 False가 반환된다.
- dropna(), fillna()
print(DF.dropna())
DF['call'] = DF['call'].fillna('전화번호 없음')
print(DF)
.dropna()는 비어있는 data가 있으면 그 data row 전체를 날린다.
.fillna()는 비어있는 곳에 채워준다.
이때, dataframe자체에 채워주는 곳이 아니라 반환해주는 메소드이므로 새로 선언해서 사용해야한다.
- Series, DataFrame 연산
A = pd.Series([2,4,6], index=[0,1,2])
B = pd.Series([1,3,5], index=[1,2,3])
print(A+B)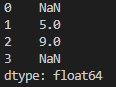
numpy는 원소끼리 사칙연산이 된다. 그럼 Series는?
index가 같은 값끼리 연산이 이루어지고, 나머지는 NaN가 반화된다.
이때, index가 같지 않은 원소의 자리에 0을 채워서 연산이 이루어지기를 원한다면?
print(A.add(B, fill_value=0))
DataFrame의 연산도 확인해보자.
A = pd.DataFrame(np.random.randint(0,10,(2,2)), columns=list("AB"))
B = pd.DataFrame(np.random.randint(0,10,(3,3)), columns=list("BAC"))
print(A+B)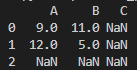
0과 10사이의 임의의 정수들을 원소로 가지는 A와 B의 연산을 하면, 위와같이 결과가 나온다.
fill_value를 가지는 함수 add(+), sub(-), mul(*), div(/)를 사용하면, NaN이 나오지 않는 연산을 할 수 있다.
집계함수는 어떻게 될까?
data = {
'A': [i*5 for i in range(3)],
'B' : [i**2 for i in range(3)]
}
DF = pd.DataFrame(data)
print(DF['A'].sum()) # 18
print(DF.sum())
print(DF.mean())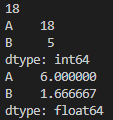
집계함수는 Series별로 이뤄지는것을 확인할 수 있다.
- Dataframe 정렬
- sort_values
df = pd.DataFrame({
'col1' : [2,1,9,8,7,4],
'col2' : ['A','A','B',np.nan, 'D','C'],
'col3' : [0,1,9,4,2,3]
})
print(df)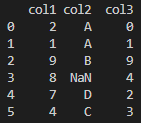
print(df.sort_values('col1'))
sort_values인자로 Series의 이름을 넣으면, Series기준으로 정렬시켜준다.
df.sort_values('col1', ascending=False)
와 같이 적으면, 내림차순으로 정렬되는것을 확인할 수 있다.
print(df.sort_values(['col2','col1']))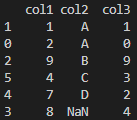
정렬 순서를 정할 수도 있다.
'Language > Python' 카테고리의 다른 글
| Pandas 심화 (0) | 2023.02.26 |
|---|---|
| Pandas_Series, DataFrame (0) | 2023.02.24 |
| Numpy_Broadcasting, masking (0) | 2023.02.23 |
| Numpy_Indexing, Slicing, Operator (1) | 2023.02.23 |
| Numpy_Create Array (0) | 2023.02.23 |

