책과 다르게 비지도학습은 data의 종류를 모른다.
이런 경우 평균값을 어떻게 구할까?
k-평균(k-means) 군집 알고리즘으로 평균값을 찾을수 있다.
이 평균값이 클러스터의 중심에 위치하기 때문에 클러스터 중심(cluster center) 또는 센트로이드(centroid)라고 부른다.
- k-평균 알고리즘

데이터 준비하고, 이를 크기 조정해준다. (sample 갯수,너비,높이) -> (sample 갯수, 너비 X 높이)
k-평균 알고리즘은 sklearn.cluster / KMeans 클래스에 구현되어 있다.
클러스터 갯수를 지정하는 n_clusters 매개변수가 있다.
비지도 학습이므로 km.fit()에 target이 없다.

cluster개수가 3이므로, 0,1,2로 분류된다.

km.labels_ 는 0,1,2로 나뉘고, 갯수는 위와 같이 된다.
그림으로 보기 위해 figure사이즈 조정해주자.

불리언 인덱싱으로 0번 클러스터로 분리된 그림들을 출력.


- 클러스터 중심
KMeans 클래스가 최종적으로 찾은 클러스터 중심은 clueter_centers_ 속성에 저장되어 있다.
이 배열은 fruits_2d 샘플의 클러스터 중심이기 때문에 이미지로 출력하려면 100x100 크기로 사이즈 조정
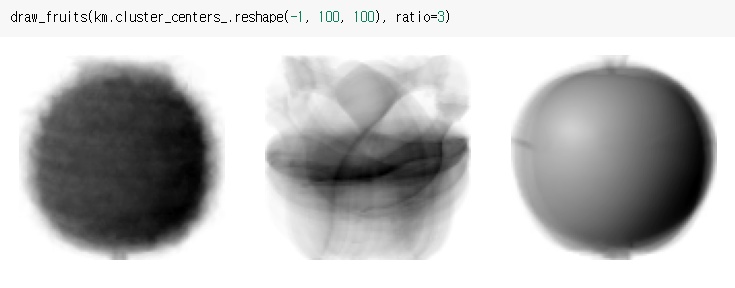
cluster의 평균 그림을 그려보면 사과, 바나나, 파인애플의 픽셀 평균값과 비슷합니다.
훈련 데이터 샘플에서 클러스터 중심까지 거리로 변환해주는 transform() 메서드를 가지고 있다.
StandardScaler 클래스처럼 특성값을 변환하는 도구로 사용할 수 있다.
transform()메서드는 fit() 메서드와 같이 2차원 배열을 기대한다. 슬라이싱으로 (10000,) -> (1,10000) 크기의 배열을 전달하자.

위에서는 100번째 샘플을 전달했고, 이는 클러스터 별 거리를 출력해준다.
km.predict()로 가장 가까운 클러스터 중심을 예측 클래스로 출력한다.
그러면 그림으로 그려볼까요?
위와 같이 파인애플이네요!
최적의 클러스터를 찾기 위한 클러스터 중심을 옮기는데, 이 반복횟수는 km.n_iter_에 저장되어 있습니다.
- 최적의 k 찾기
군집 알고리즘에서 적절한 k 값을 찾기 위한 완벽한 방법은 없지만, 몇 가지 도구가 있다.
대표적인 방법으로 엘보우(elbow) 방법에 대해 알아보자.
k-평균 알고리즘은 클러스터 중심과 클러스터에 속한 샘플 사이의 거리를 잴 수 있다.
이 거리의 제곱 합을 이너셔(inertia)라고 부른다.
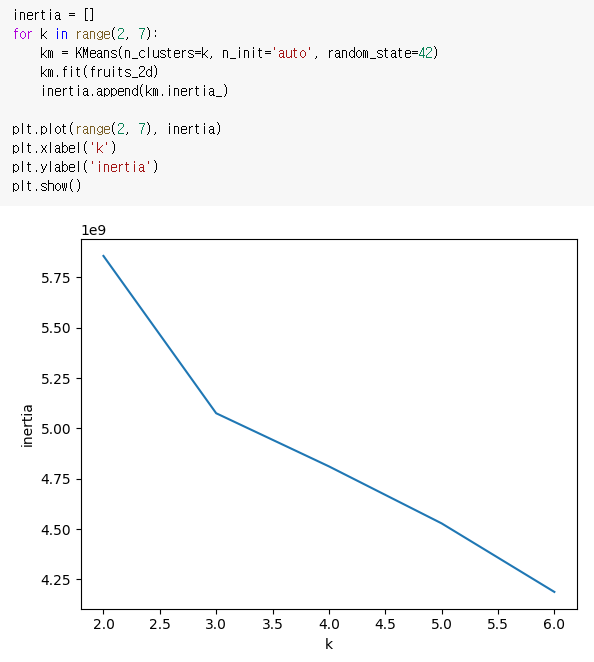
최적의 k를 찾기위한 이너셔 값을 k값에 따라 그림으로 표현하자.
최적의 클러스터 개수 = 클러스터 개수와 이너셔 값의 그래프가 꺾이는 지점
km.inertia_에 inertia 저장되어 있습니다.
- k-평균 알고리즘
- 클러스터 중심 or 센트로이드
- 엘보우 방법
- KMeans



'DATA & AI > HG ML&DL' 카테고리의 다른 글
| [HG ML&DL] 06. 비지도 학습 (1) - 군집 알고리즘 (0) | 2023.05.03 |
|---|---|
| [HG ML&DL] 05. 트리 알고리즘 (3) - 트리의 앙상블 (0) | 2023.05.03 |
| [HG ML&DL] 05. 트리 알고리즘 (2) - 교차 검증과 그리드 서치 (0) | 2023.05.02 |
| [HG ML&DL] 05. 트리 알고리즘 (1) - 결정 트리 (0) | 2023.05.02 |
| [HG ML&DL] 04. 다양한 분류 알고리즘 (2) - 확률적 경사 하강법 (0) | 2023.05.02 |



