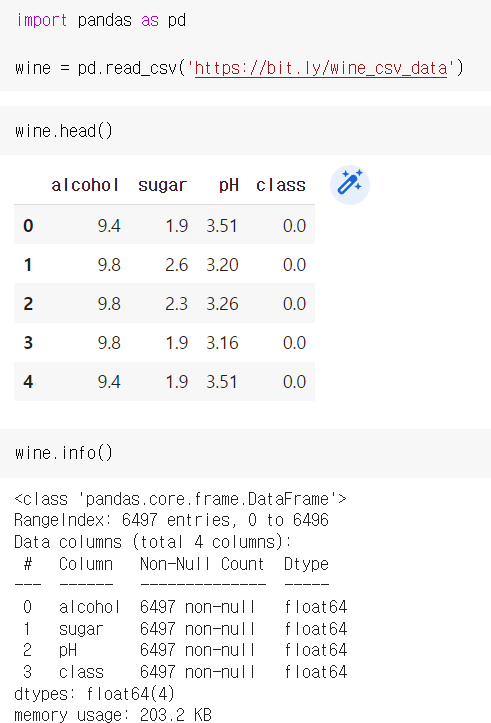
이번에는 로지스틱 회귀로 와인을 분류하는 것부터 시작한다.
DataFrame.head()는 처음 5개의 샘플을 가져온다. 그리고 info() 로 누락된 데이터가 있는지 확인한다.
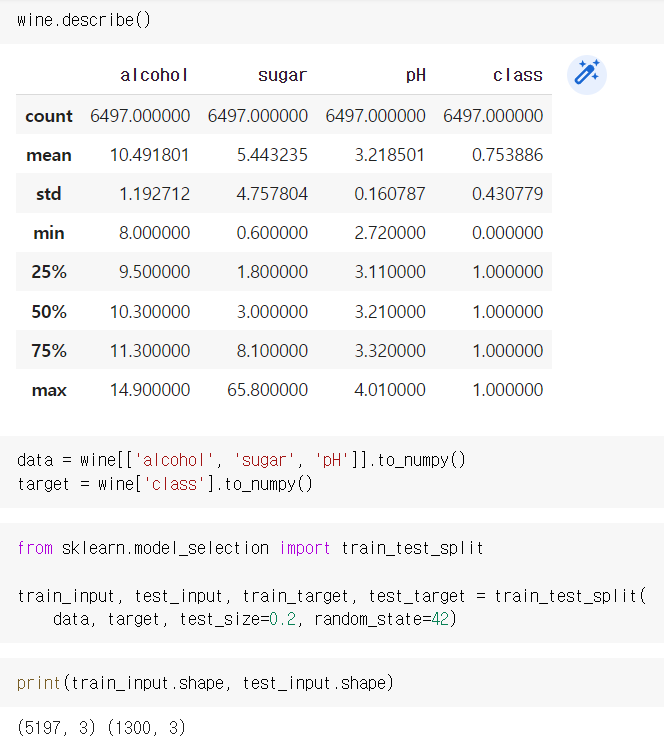
data와 target 생성 후, split 하고, input.shape을 확인한다.

데이터 전처리 후, LogisticRegression() 객체 모델을 생성하고, 학습, 정확도를 본다.
그리고, 계수와 절편을 출력했다. input의 특성이 3개니까, 3차 다항식의 계수가 나온다.
- 결정 트리 (Decision Tree)
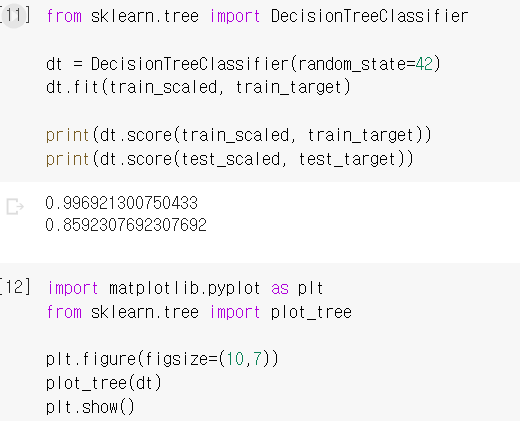

sklearn.tree / DecisionTreeClassifier 객체를 생성하고, 똑같이 학습해줬습니다.
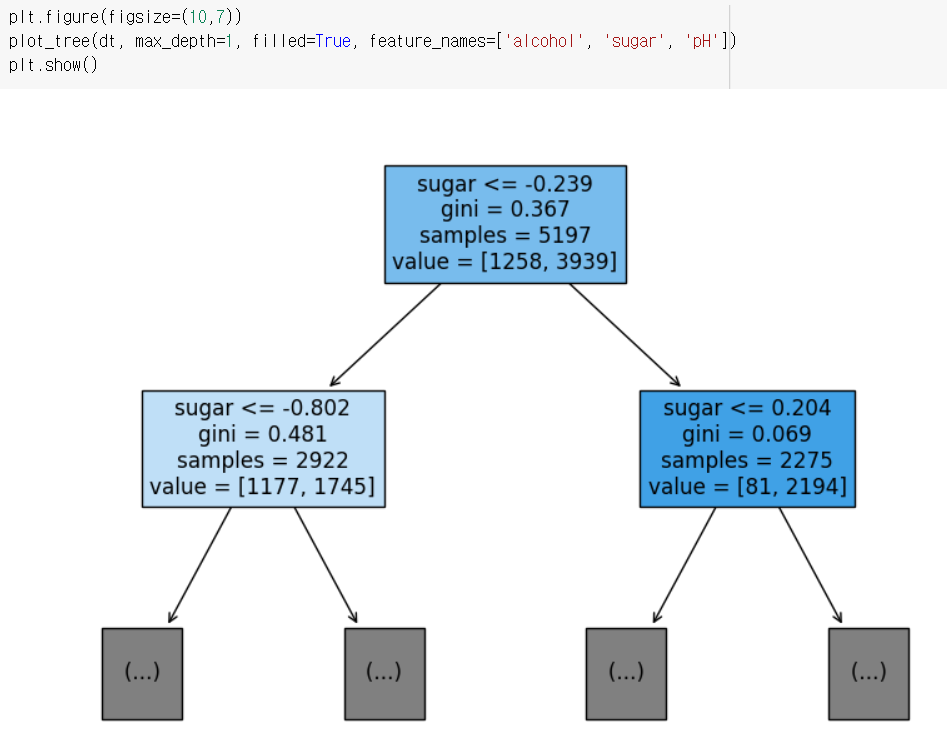
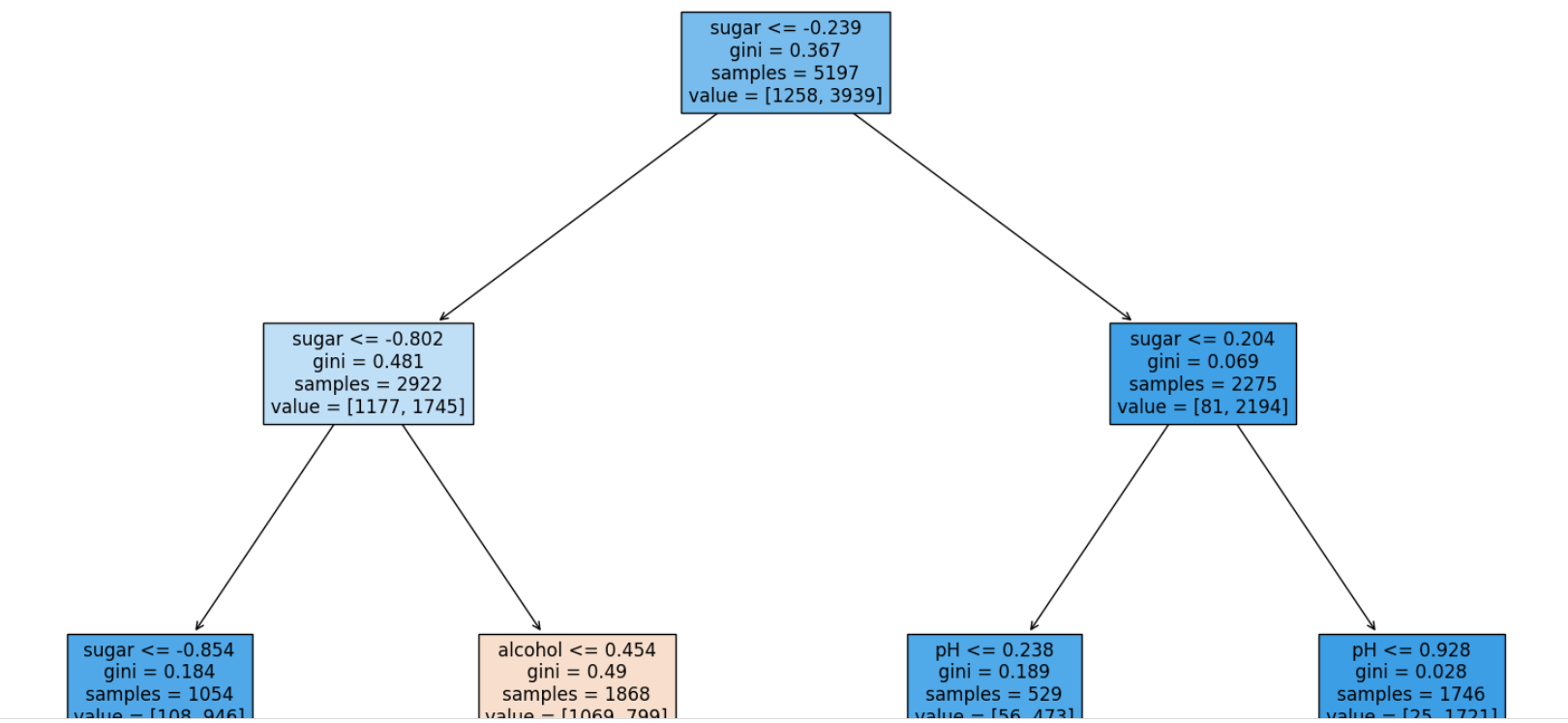
tree를 그릴때, max_depth=1로 층을 제한하고, 그림으로 확인할 수 있다.
filled 매개변수는 노드의 색을 칠할 수 있고, feature_names로 특성의 이름을 전달할 수 있다.
노드의 적힌 내용을 위에서 순서대로 말하자면,
테스트 조건(feature)
불순도(gini)
총 샘플 수(samples)
클래스별 샘플 수(value)
지니 불순도 = 1 -(음성 클래스 비율^2 + 양성 클래스 비율^2)
부모와 자식 노드 사이의 불순도 차이를 정보 이득(information gain) 이라고 합니다.
- 가지치기


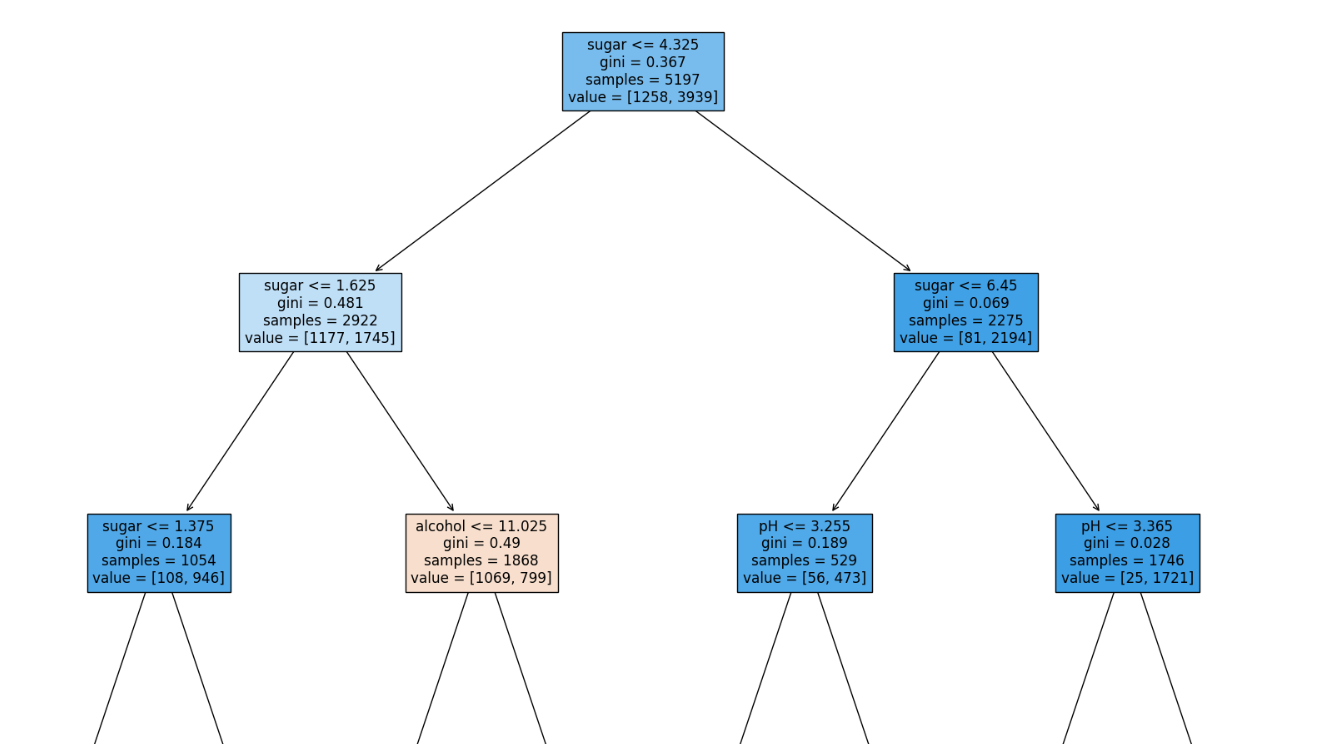
전처리를 하지 않아도, 정확도는 똑같이 나온다.
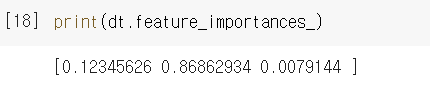
feature_importances_ 속성으로 각 특성별 중요도를 확인할 수 있습니다.
루트 노드와 깊이 1에서 당도를 사용했기 때문에 가장 유용한 특성으로 나오는 것을 확인할 수 있습니다.


결정 트리는 데이터 전처리를 하지 않아도 정확도가 나온다.
- 결정 트리
- 불순도
- 정보 이득
- 가지치기
- 특성 중요도
- DecisionTreeClassifier
'DATA & AI > HG ML&DL' 카테고리의 다른 글
| [HG ML&DL] 05. 트리 알고리즘 (3) - 트리의 앙상블 (0) | 2023.05.03 |
|---|---|
| [HG ML&DL] 05. 트리 알고리즘 (2) - 교차 검증과 그리드 서치 (0) | 2023.05.02 |
| [HG ML&DL] 04. 다양한 분류 알고리즘 (2) - 확률적 경사 하강법 (0) | 2023.05.02 |
| [HG ML&DL] 04. 다양한 분류 알고리즘 (1) - 로지스틱 회귀 (0) | 2023.05.01 |
| [HG ML&DL] 03. 회귀 알고리즘과 모델 규제 (3) - 특성 공학과 규제 (0) | 2023.05.01 |



